CPU 缓存梳理及探讨
Contents
1. 概述
本来写这篇文章的出发点是想要梳理一下,工作中常用到的 cache,借此为自己的知识体系做一个总结和深化。但是,总感觉简单地梳理又不那么令人满足,于是打算开启一个 cache 系列,分模块对 cache 进行一个深入浅出的总结。在这些总结中,每一章都各有自己的侧重点,从不同的角度,归纳和剖析我们日常使用的 cache 技术。
这一章的主要内容是: 对 CPU cache 进行梳理并探讨其中有趣的点。希望借助最为经典和深刻的 CPU cache 架构,我们能够找到 cache 体系的设计思想和逻辑。
2. 常用缓存梳理
在平时我们常见的缓存大致可以分为硬件缓存和软件缓存 1。大致如下:
-
hardware
- CPU cache
- gpu cache
- TLB
- …
-
software
- disk cache
- web cache (nodebb)
- CDN
- Cloud storage (s3, cloud)
- DNS
- DB cache
- Distributed cache
- …
3. CPU 缓存梳理及探讨
CPU 是计算机世界中几乎是最微观的底层硬件。在现在的计算机架构下,无论我们编写什么样的程序,最后都会交付给 CPU 执行和计算,可以说 CPU 就是计算机组成中核心中的核心。由于 CPU 的特殊之处,现代的工程师花费了大量精力围绕 CPU 进行性能优化,其中的优化点之一,就是引入缓存设计。这可以说是提升 CPU 利用率的最关键一点。
3.1 为什么要引入 CPU 缓存
最早期的 CPU 并没有引入 cache,CPU 直接从存储器中读取指令和数据到寄存器中执行。说到底,引入缓存的考量都是基于对性能和速度的渴求。如果没有缓存,CPU 将会一直处于等待数据传输的过程中,大量的 CPU 时钟周期将会被浪费,而且在早期由于 CPU 制程和工艺的不断进步,CPU 处理速度和存储器存取之间的差距在不断增大。
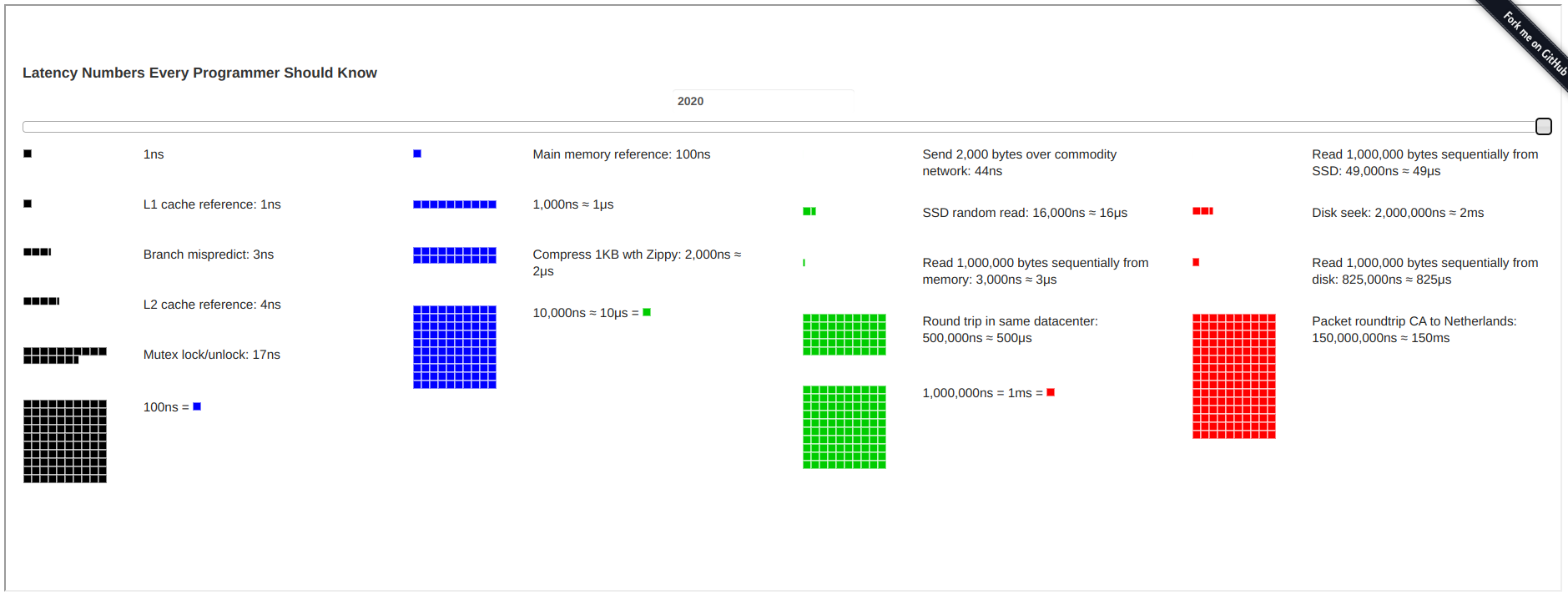
各级缓存的延迟数字可以见下图2:
还有一张很著名的表格3,对应的时间应该是 2012 年,按照实际时间进行排序:
| Work | Latency |
|---|---|
| L1 cache reference | 0.5 ns |
| Branch mispredict | 5 ns |
| L2 cache reference | 7 ns |
| Mutex lock/unlock | 25 ns |
| Main memory reference | 100 ns |
| Compress 1K bytes with Zippy | 3,000 ns |
| Send 1K bytes over 1 Gbps network | 10,000 ns |
| Read 4K randomly from SSD* | 150,000 ns |
| Read 1 MB sequentially from memory | 250,000 ns |
| Round trip within same datacenter | 500,000 ns |
| Read 1 MB sequentially from SSD* | 1,000,000 ns |
| Disk seek | 10,000,000 ns |
| Read 1 MB sequentially from disk | 20,000,000 ns |
| Send packet CA->Netherlands->CA | 150,000,000 ns |
虽然说具体数字上会有差异,我们可以看到, L1 的速度大概是 L2 的 7-14 倍,差不多是主存(main memory) 的 1~200 倍,相差两个数量级,这种性能上的差距导致 CPU 的设计者引入了中间缓存来提升 CPU 的利用率。但是从实际的硬件大小上看, L1/L2 是 KB 级别的缓存,L3 一般会是 MB 级别的,主存则是 GB 级别的。
3.2 CPU 缓存实例
公司的某型号设备,使用的是某 A 公司生产的,架构为 ARM Cortex-A9 的 soc 芯片,根据官网的介绍,这种架构是:
The Cortex-A9 processor features a dual-issue, partially out-of-order pipeline and a flexible system architecture with configurable caches and system coherency using the ACP port. The Cortex-A9 processor achieves a better than 50% performance over the Cortex-A8 processor in a single-core configuration.
和 cache 有关的参数有:
| cache 级别 | 容量大小 |
|---|---|
| L1 cache | 32 KB I, 32 KB D |
| L2 cache | 128 KB–8 MB (configurable with L2sr1 cache controller) |
使用同样架构的 soc 芯片还有 Apple A5,于 March 11, 2011 发布,搭载在
-
iPad 2
-
iPhone 4S
-
Apple TV (3rd generation)
-
iPod Touch (5th generation)
-
iPad Mini (1st generation)
-
Apple TV (3rd generation Rev A)
另外一个比较新的例子是 M1 芯片,苹果公司在 2020 年发布:
| cache 级别 | 容量大小 |
|---|---|
| L1 cache (high-performance) | 192 KB I, 128 KB D |
| L1 cache (efficient) | 128 KB I, 64 KB D |
| L2 cache (high-performance) | 12 MB |
| L2 cache (efficient) | 4 MB |
| L3 cache | 8 MB |
3.2.1 怎么查看 CPU 的缓存大小
查看电脑、设备 CPU 的详细信息可以通过以下方式:
-
系统提供的 gui(略)
-
登入 tty,输入命令获取
一般可以通过以下命令获取:
- Linux 系统:
|
|
- Windows
|
|
- 系统文件、运行时数据
在 linux 下,另外的方式是直接查看 /proc 文件夹下的文件:CPUinfo
在 Linux 系统中,这是一个特殊的文件夹,里面包含了 kernal 会用到的信息,比较特别的是里面的“文件” 大小都是 0(除了 kcore, mtrr 和 self)
3.3 什么是 CPU 缓存
3.3.1 CPU 缓存的历史
CPU(central processing unit) 是什么时候诞生的?早在 1955 年,CPU 这个词就已经出现了 4。但是如果按照 CPU 的定义: 用来执行程序的设备,那么最早 CPU 的历史可以被追溯到 1945 年 6 月 30 日,出现在 John von Neumann 发布的论文 First Draft of a Report on the EDVAC (First Draft) 中 5。
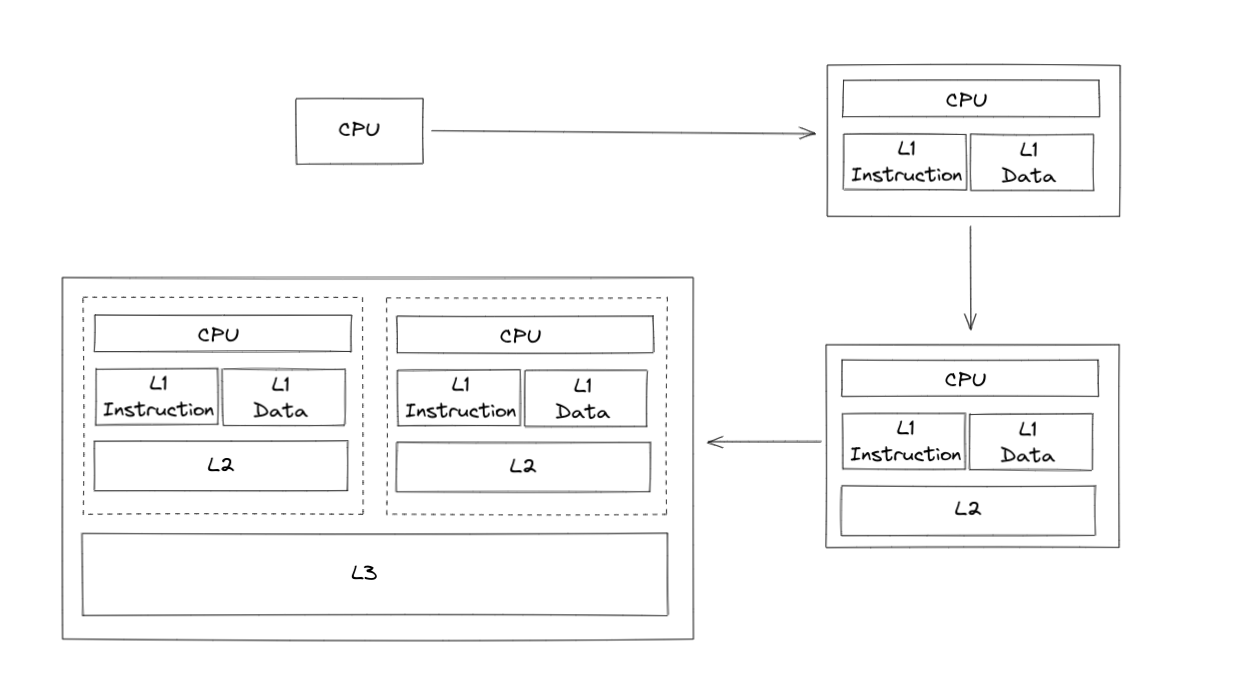
但是,CPU 在诞生的初期,最顶尖的学者也没有意识到,CPU 需要引入缓存的概念————一直到 1960s,人们才为 CPU 引入了缓存,而且这种初级的缓存甚至只有一级(L1),没有我们今天常见的 L2/L3 级缓存。L1D/L1I 缓存的引入也是直到 1976 年 (IBM 801) 才出现。演变过程可以见下图:
3.3.2 一些 CPU 缓存相关的基础知识
- L1 缓存分成两种,一种是指令缓存 (L1-I),一种是数据缓存 (L1-D)。L2 缓存和 L3 缓存一般不分指令和数据
- L1 和 L2 缓存在每一个 CPU 核中,L3 则是所有 CPU 核心共享的内存
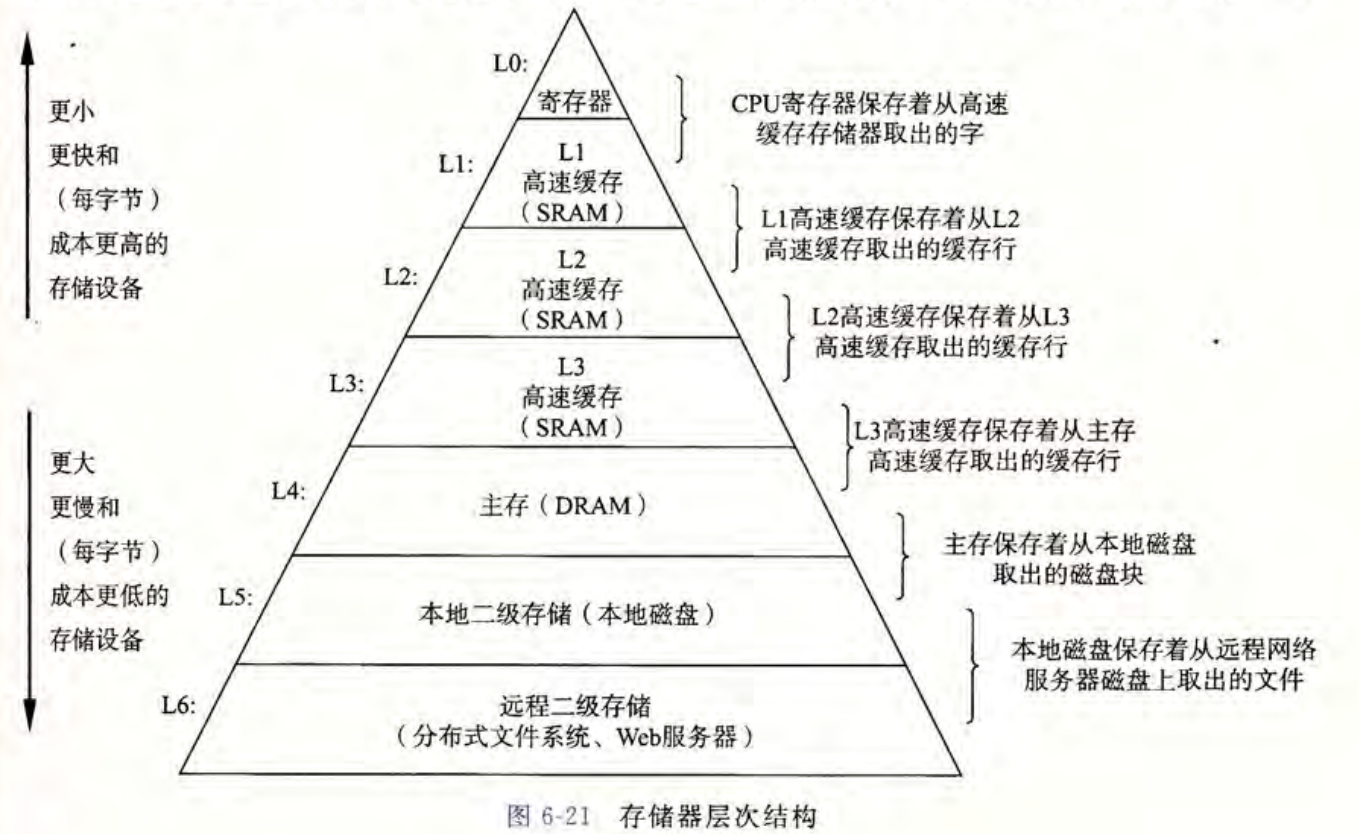
其他的一些存储器如下图5所示:
SRAM vs DRAM
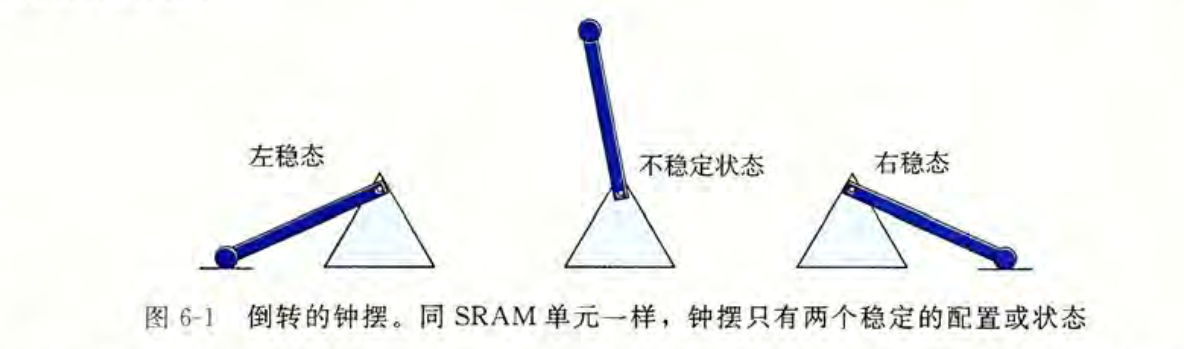
SRAM 将每个位存储在一个双稳态的(bistable)存储器单元里。
SRAM 的特性使得它不会因为干扰而发生值的变化。
与 SRAM 不同,DRAM 存储器单元对干扰非常敏感,甚至会因为受到光线的影响而改变电压。
这决定了他们的用途和造价上的差异。
Q
看到这里有一个不明显但是值得思考的问题是,同样是 SRAM 类型的缓存芯片,为什么 L1 的速度要比 L2/L3 的缓存快那么多?
A
可以从三个角度来解释这个问题:
- 空间排布
首先从物理角度上来说,在同样的介质中传输同样的物体需要消耗的时间,会随着传输距离的增大而增加;L1 cache 的分布位置比起 L2/L3 距离 CPU 更近。
其次信号在芯片、晶体管中传输的实际速度远小于光速,这个速度大概是: 30cm/ns。所以在一块芯片大小的空间上,位置影响到了实际的传输延迟。
- 容量大小
L2 的容量要大于 L1 ,如果要构建更大容量的芯片,实际上就需要更多的晶体管,这起始也影响到了 距离 这个参数,因为访问最远的晶体管变得更慢了,因为信号需要传输的路径变长得更长了。
- 密集程度
更小容量的缓存,可以设计为制造的时候采用更大的晶体管,提升芯片的整体性能。
我们来看一张 VIA Isaiah 处理器的结构图,如图所示:
- cache-line/cache-entries
来了解一下 CPU 缓存中的存储方式,这里需要明白一个术语 cache-line,这个东西其实和我们学到的其他计组硬件的所谓 块、页差不多,实际上就是等量的对整个芯片的容量进行划分。
比如说,我们的 CPU 采取的是大小为 64B 的 cache-line,那么一个大小为 32KB 的 L1D 所存储的cache-line 个数就是: 32KB/64B = 512 个 。
除了对容量进行划分,还有一个关键点就是,如何寻址。实际上寻址可以看作是 数据块 的 tag、key,这和我们经常使用的 map,redis 里面的 key 索引,sql 里面的主键索引,起到的作用一模一样,就是需要根据这个 key,找到对应的数据。这就是另一个 cache 的关键知识点:地址关联。
具体的地址关联知识不在这里继续展开了,感兴趣的朋友可以自行了解(复习)。
3.4 多级缓存引入的问题
多级缓存看上去是一个很美好的实现,每一层存储介质都是下一层的缓存,只要找不到就继续往下一层找。但是现实是残酷的,多级缓存带来了高性能,也引入了下面两个问题:
- 缓存 miss 的处理问题
- 缓存一致性问题(多核)
3.5 CPU 中的缓存更新实践
Read-Through
前文有讲到,CPU 会采取 read-through 的策略读取数据,降低时延。我们主要来讲发生 缓存 miss 的时候,需要采取什么样的操作。
如果是读取的时候发生 cache miss,CPU 就会试图向更低一层的 cache 读取数据,读取到的数据会被引入到当前缓存中,这个时候就需要 淘汰算法 (Replacement policies) 来处理。
淘汰算法主要有两种,一种是随机淘汰,一种是 LRU(least-recently used)。一般来说都是采取的 LRU 算法。
Write-Through
当 CPU 执行了写操作的时候,从 cache 这一层存储层一直到硬盘都需要更新。这个时候有两种更新策略可供选择: write-through 和 write-back。我们先来讲前者。
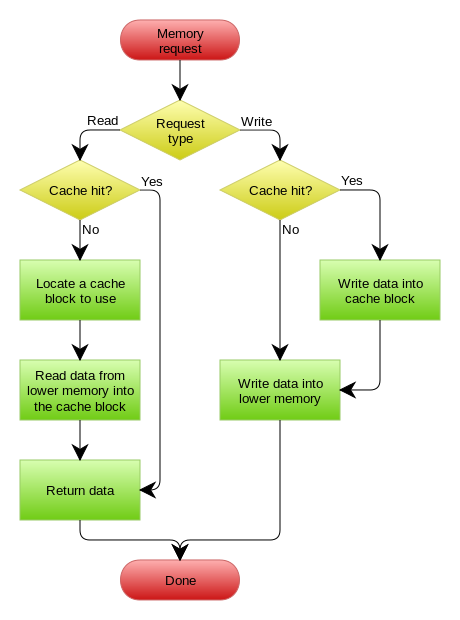
采取 Write-Through 操作的时候,CPU 中所有的写操作会经过所有级别的 cache,最后缓存会把数据持久化到对应的硬盘/磁盘中去。
Write-Back
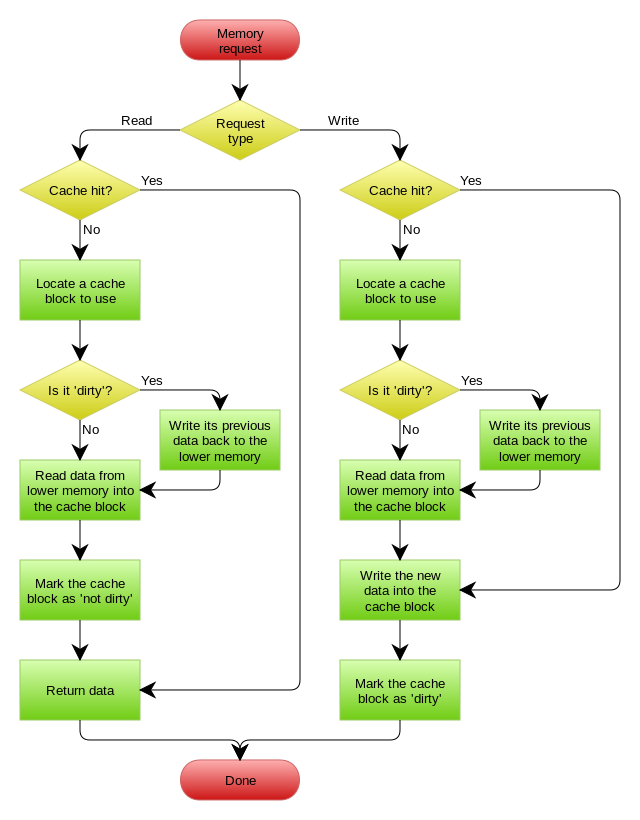
Write Back,其实就是在更新数据的时候,只更新缓存,不把内容更新到主存里面去,而我们的缓存会异步地批量更新主存。这个设计的好处就是让数据的 I/O 几乎都是在缓存中进行的。这样一来,更新操作飞快无比,最重要的是,由于时间和空间局部性的作用,Write Back 很有可能会合并对同一个数据的多次操作,这导致最后 Write Back 对性能的提高变得相当可观。
Write Back 虽然说带来了性能上的质的提升,但是他也有一个致命缺点,那就是数据一致性无法保证,甚至丢失也是有可能的。
这就类似于我们在软件设计上的 Trade-Off,一个没有缺陷的设计很难被我们碰上,一般碰上的都是取舍问题,就像算法设计中,很多时候我们需要牺牲空间换取时间;在分布式设计中,CAP 原则等等。
文献引用
- [1] wiki-Cache
- [4] wiki-CPU-history
- [6] 深入理解计算机系统
Author Bitnut/三口一个瓜
LastMod 2022-11-08